Witajcie,
codintv(); z założenia ma być wideo-blogiem jednak ze względu na okres urlopowy dzisiaj nie jesteśmy w stanie opublikować nowego nagrania. W zamian publikujemy naszym zdaniem ciekawy artykułpost odnośnie wzorca repozytorium.
Temat ten został poruszony w komentarzach do poprzedniego odcinka 09. Repozytorium User. Powstała tam ciekawa dyskusja na temat sensu wykorzystania wzorca repozytorium w naszym projekcie. Poprosiłem o komentarz znajomego i jego odpowiedź zamieszczam poniżej (za długie to było na komentarz 🙂 )
Autor: Norbert Raus – web development manager, architect. Zainteresowania: compilers, decompilers, debuggers, parsers, lexers, concurrency, threading. Blog: http://insightpassion.com
Wzorzec projektowy: Repozytorium
Streszczenie
W niniejszym artykule postaram się rozwinąć znaczenie wzorca projektowego Repozytorium (ang. Repository), nawiązując do jego historii powstania oraz idei, która przyświecała stworzeniu owego rozwiązania. W dalszej części, w oparciu o literaturę, przedstawię różne formy wzorca oraz jego zastosowania. Moim głównym celem tego artykułu jest przekazanie praktycznej wiedzy na temat użycia omawianego wzorca wraz z pogłębieniem wiedzy na temat wzorców projektowych.
W dalszej części artykułu będę posługiwał się terminem Repozytorium w ścisłym odniesieniu do omawianego wzorca projektowego.
Wszystkie wyrażone opinie i wnioski przedstawiają wyłącznie mój własny punkt widzenia i niekoniecznie prezentują opinię mojego pracodawcy.
Koncepcja wzorca projektowego
Wiele zostało napisane na temat koncepcji wzorców projektowych i chyba jeszcze więcej na temat przeróżnych sposobów ich wykorzystania. Nie mniej jednak, nie sposób omówić założeń Repozytorium bez ówczesnego zwięzłego wprowadzenia w przestrzeń wzorców projektowych. Niemal każdy z wzorców, którymi w większym lub mniejszym stopniu obecnie się posługujemy, powstał głównie z zamiarem rozwiązania pewnego określonego problemu (lub też grupy powiązanych problemów). Każde rozwiązanie jednak, ma to do siebie że jest w pewnym stopniu skorelowane ze szczegółową przestrzenią problemu, którego dotyka. Wzorzec projektowy stara się to powiązanie uogólnić, dostarczając rozwiązanie “wystarczająco dobre” dające się zastosować w większym zakresie problemów. Nie znaczy to jednak, że ta uogólniona przestrzeń problemu pozbawiona jest ograniczeń i założeń. Innymi słowy, owo “wystarczająco dobre” rozwiązanie potrafi nieść ze sobą dodatkowy wysiłek związany z utrzymaniem, tworzeniem kodu lub też wymaga kompromisów dotyczących bardziej technicznych stron jak np. wydajność systemu. (dyg. myślę, że z tego właśnie powodu istnieje wiele bardzo podobnych wzorców projektowych posiadających pokrewne cechy, ponieważ każdy z nich znajduje lepsze zastosowanie w szczegółowym zakresie problemu, będąc w tym samym czasie “wystarczająco dobrymi” rozwiązaniami w ogólnym podejściu). Warto sobie uświadomić że my jako architekci i programiści musimy na te kompromisy przystać, świadomie podejmując decyzję, który wzorzec użyć lub też go pominąć. Ta świadomość opiera się głównie na szczegółowej analizie problemu oraz rzeczywistości, w której wybrany wzorzec ma znaleźć zastosowanie.
Wzorzec Repozytorium, jak większość wzorców, jest formą dodatkowej abstrakcji, którą wprowadzamy do naszego systemu. Z lingwistycznego punktu widzenia, słowo abstrakcyjny (ang. abstract) znaczy oderwany, odłączony, oddzielony. Innymi słowy, znaczy to tyle że tworzymy abstrakcje po to aby oderwać jedną część układanki od drugiej. Zatem abstrakcja jest zawsze w relacji to czegoś innego a niekoniecznie jest bytem samym w sobie z punktu widzenia programistycznego. Jak to odnosi się do nas jako programistów? Wzorce projektowe, w tym Repozytorium, powinny być używane wtedy gdy jest taka konieczność (relacja do problemu) a nie jak to się często spotyka kiedy to problem jest dopasowywany (zmieniając często wymagania projektowe) do zastosowanych wzorców w projekcie. Kontynuując ten wątek, z mojej własnej perspektywy, dogłębne rozumienie koncepcji i idei stojącej za danym rozwiązaniem, w naszym przypadku wzorca Repozytorium jest kluczowe! Chowanie się za sloganami rzucanymi w kierunku wzorców projektowych (włączając opnie pozytywne i negatywne) bez kwestionowania sensowności i rzeczywistości własnego zastosowania, jest w mojej opinii po prostu złe. Prowadzi to do przyzwyczajeń, niekoniecznie dobrych, które znajdują swoje miejsce w systemach/kodzie który tworzymy. Postarajmy się zatem szczegółowo przyjrzeć i zanalizować różne zastosowania wzorca Repozytorium (warto również nadmienić znaczenie słowa Repozytorium (ang. repository) które oznacza magazyn, składnicę oraz przechowalnie).
Formalna definicja i zastosowanie
Chciałbym oprzeć się na bardziej formalnej definicji Repozytorium i jego zastosowaniu według Martina Fowlera (P of EAA : Repository), Erica Evansa (DomainDrivenDesignQuickly) oraz wspierając się znakomitą książką Dino Esposito (Architecting Microsoft® .NET Solutions for the Enterprise). Fowler (Patterns of Enterprise Application Architecture) pisze, że Repozytorium pośredniczy pomiędzy warstwą Logiki biznesowej (domeny – warstwa opisująca/modelująca daną dziedzinę) a warstwą Mapującą (Data Mapper) dostęp do bazy danych. Pisze on dalej, że w systemach z rozbudowaną logiką biznesową, modelujących dość złożoną dziedzinę, w których stosuje się wzorzec „Data Mapper”, sensowne może okazać się zastosowanie dodatkowej warstwy, która umożliwi lepszą organizację oraz konstrukcję zapytań minimalizując stopień powielania tych samych zapytań. Dalej pisze, że wzorzec powinien prezentować bardziej spójny model obiektowy, posiadając cechy kolekcji obiektów przechowywanych w pamięci. Model ten powinien umożliwić deklaratywny sposób wyrażania wymagań/chęci odnośnie obiektów którymi warstwa biznesowa jest zainteresowana.
Evans w swojej książce „Domain Driven Design” skupia się bardziej od strony problemów, które związane są z używaniem obiektów domenowych. Zwraca on uwagę na konieczność oderwania logiki biznesowej/domeny od kwestii związanych z zapisem/przechowywaniem w bazie danych. Innymi słowy obiekty używane w logice biznesowej powinny posiadać cechę tzw. „persitence ignorance”, czyli w wolnym tłumaczeniu być nieświadome technologi zastosowanej do zapisu i odtworzenia stanu obiektu (utrzymywania trwałości). Prezentuje on również dwa warianty podejścia do tworzenia Repozytorium. Pierwsze sugeruje stworzenie repozytorium ze ściśle określonym interfejsem dostarczającym jedynie wymagane metody:
public interface ICustomerRepository
{
Customer FindCustomer(string id);
void AddCustomer(Customer customer);
//inne methody zwiazane z repozytorium
}
Drugie pozwala na bardziej deklaratywny sposób używanie Repozytorium przy tworzeniu zapytań, z wykorzystaniem wzorca Criteria (Specification):
public interface ICustomerRepository
{
Customer FindCustomer(ICriteria criteria);
void AddCustomer(Customer customer);
//inne methody zwiazane z repozytorium
}
Przestawia też ciekawy punkt widzenia, w którym stwierdza że Repozytorium może być postrzegane (posiada pewne cechy) jako swojego rodzaju Factory (Fabryka), gdzie instancje nie są tworzone „od zera” ale raczej reaktywowane (ang. reconstituated – odtwarzane, odnawiane). Przestrzega jednak, że różnica jest znacząca i nie należy mieszać tych dwóch wzorców.
Repozytorium w praktyce
Mam nadzieję, że poprzednie paragrafy wprowadziły nas w kontekst dyskusji na temat omawianego wzorca. W naszej społeczności programistów, spotyka się często brak zgody odnośnie znaczenia poszczególnych wzorców. Jako krótką dygresja dodam że, jednym z dodatkowych powodów wprowadzenia wzorców, o którym nie wspomniałem wcześniej, miało być na celu zunifikowanie języka jakim specjaliści posługują się na co dzień, poprzez nadanie dobrze zdefiniowanych problemom i rozwiązaniom swoich nazw. Dlatego zaczęliśmy od przypomnienia bardziej formalnej definicji, o którą w dalszej części artykułu będę opierał moją dyskusję, czyli o rozumienie wzorców projektowych i wzorca Repozytorium przedstawionych w poprzednich paragrafach.
Z praktycznych kwestii, chciałbym na wstępie poruszyć i odnieść się do kilku opinii, które można często spotkać podczas dyskusji o wzorcu Repozytorium:
Mantra #1—It Depends.
It always depends. As an architect, you are never sure about anything. There’s always the possibility that you’re missing something (…) [Dino Esposito, Architecting Microsoft® .NET Solutions for the Enterprise]
1) „Używanie wzorca Repozytorium jest z założenia błędne”
Stwierdzenie to jest trochę wyrwane z kontekstu, dlatego też można się z nim zgodzić bądź nie. To po prostu zależy od… Nie mniej jednak sama koncepcja wzorca Repozytorium jest jak najbardziej sensowna i ma swoje uzasadnienie. To co ja uważam za błędne to trzymanie się ortodoksyjnych wizji, bez wcześniejszego wgryzienia się w problem (zgodnie zresztą z Mantrą #1 Dino Esposito). Wydaje mi się, że problem leży trochę gdzie indziej, nie w samym założeniu Repozytorium, lecz w sposobie w jaki przyzwyczailiśmy się do używania Repozytorium, mianowicie jako swoistego rodzaju opakowania (ang. wrapper) na technologie ORM jak NHib/L2S/EF. Jeżeli spojrzymy ponownie na definicję oraz przykłady podane przez Fowlera i Evansa, dostrzec można, że obecne technologie ORM same w sobie dostarczają abstrakcję, która zdradza cechy repozytorium. Deklaratywny sposób używania LINQ (drugi wzorzec Repozytorium wg. Evansa) jest praktycznie dostępny wraz z obecną technologią ORM . Fowler i Evans w swoich publikacjach opisują rzeczywistość, w której Repozytorium składało się głównie z „czystych” zapytań SQL. Wniosek z tego, że używanie Repozytorium jako opakowania na ORM jest zdecydowanie mniej sensowne i może prowadzić do niepotrzebnej abstrakcji. Kiedy jednak może okazać się wskazane? Otóż, idąc tropem jaki Martin Fowler wyraża w subtelnym stwierdzeniu „sensownym może okazać się”, warto rozważyć użycie Repozytorium w projekcie z rozbudowaną logiką biznesową i skomplikowaną domeną. W systemach takich, modelowana dziedzina, wraz z logiką biznesową znajduje się w centrum systemu – jest najważniejsza oraz najtrudniejsza to wymiany. Jeżeli projektujemy tego rodzaju system, warto podążyć za wskazaniami Evansa i odseparować „centrum systemu” od kwestii związanych z infrastrukturą, jaką jest sposób „zapisu/odtwarzania stanu”.
2) „Repozytorium pozwala na testy jednostkowe”
I tak i nie, zależy… Otóż, obecnie dostęp do lekkich baz danych ładowanych do pamięci, takich jak SqlLite, SqlCompact wraz z użyciem wspomnianych wcześniej technologii ORM (nie wszystkie wspomniane technologie posiadają wbudowane wsparcie do wspomnianych silników baz) , sprawia, że możemy bezpośrednio wykonywać nasze testy (pozostawiam polemikę na temat czy to jest test jednostkowy czy integracyjny) „podpinając” takowe lekkie bazy (wiąże się to z dodatkowymi technikami które można/należy wykorzystać w swoich testach do utrzymania powtarzalności testów np. http://xunitpatterns.com/Transaction%20Rollback%20Teardown.html). Nie jest to jednak zawsze możliwe, ponieważ wspomniane „lekkie bazy” nie zawsze wspierają wszystko to co „standardowe” silniki silniki baz. Jako przykład można podać, brak wsparcia dla procedur wbudowanych (ang. stored procedures – pozostawiam polemikę na temat czy warto używać procedur wbudowanych czy nie) czy też ograniczone komendy SQL. Jakkolwiek dla wielu małych projektów te ograniczenia mogą nie być problemem, to w większych systemach te ograniczenia są po prostu nie do obejścia. Mam tutaj na myśli systemy rozwijane przez lata (tzw. „lagacy code”) w których nowe komponenty integrując się z obecną platformą. Zatem warto rozważyć używanie lekkiej bazy kiedy projekt nie posiada w/w ograniczeń.
3) „Repozytorium pozwala na późniejszą podmianę bazę danych”
To stwierdzenie brzmi dość kontrowersyjnie lecz pomimo tego wiele osób ulega temu złudzeniu i argumentuje tylko tym użycie wzorca Repozytorium. Myślę, że do czasu kiedy naprawdę muszą tą technologię podmienić… Jeżeli jednak przeformułujemy lekko powyższe zdanie stwierdzając, że Repozytorium jako abstrakcja odrywa cześć systemu od bazy danych, można wnioskować że ta abstrakcja może być pomocna. Nie zawsze będzie, bo zmieniając technologię z relacyjnych baz danych na bazę dokumentową, wkraczamy w inną przestrzeń przechowywania danych, gdzie „relacyjny” interfejs Repozytorium może nie mieć sensu. Jednakże zgodzę się również z opinią Evansa o potrzebie projektowania domeny odseparowanej od infrastruktury. Zdarzają się jednak duże projekty, kiedy kilka zespołów pracuje nad różnymi aspektami systemu i jeden może użyć Repozytorium jako interfejs wokół warstwy dostępu do danych (niektóre firmy, włączając mojego obecnego pracodawce posiadają własną technologie ORM). W tym przypadku decyzja może zostać odsunięta w czasie lub też ulec zmianie w trakcie projektu. Zatem, stawianie powyższego argumentu jako główny jest ryzykowne, warto jednak dostrzegać zalety odseparowania w sytuacji w której powyższe sytuacje mogą nastąpić.
4) „Repozytorium ogranicza możliwość korzystania z wbudowanych cech ORM”
Jakie cechy/właściwości mam tu na myśli? Lazy/eager loading, optymalizacja zapytań, użycie cache-u oraz paczkowanie zapytań (batching). Faktem jest, że użycie wzorca Rezpozytorium, ograniczę w pełni wykorzystanie wspomnianych cech. Faktem jest również, że dostępne technologie ORM różnią się pod względem dodatkowych mechanizmów. Zatem jeżeli chcemy skorzystać z cech które dostarcza NHib, musielibyśmy udostępnić interfejs specyficzny dla tego frameworka, co ewidentnie sugeruje, że Repozytorium będzie tylko utrudnieniem na naszej drodze. Istnieje jednak pewien stopień manewru, w którym możemy pomóc opakowanemu ORM-owi zoptymalizować nasze zapytania. Mam tu na myśli stosowanie „iterators block”, z wykorzystaniem słowa kluczowego yield return czy też użycie wbudowanych AST (Abstract Sytaxt Trees) z wykorzystaniem klasy Expression. Utilizacja cache-u może zostać wsparta poprzez użycie własnej implementacji, natomiast grupowanie wielu operacji można próbować zastąpić poprzez wzorzec UnitOfWork. W praktyce, techniki te są dość skomplikowane i wymagają większego nakładu pracy, zatem warto mieć świadomość, że używanie Repozytorium ogranicza możliwość wykorzystania wspomnianych cech.
5) „@codingtv();: Repozytorium pozwala na późniejsza podmianę ORM”
Myślę, że poprzednie odpowiedzi w szczególności 4) pokazują, że to stwierdzenie nie zawsze będzie łatwą drogą. Interesujące byłoby pokazanie w codingtv(); innej ścieżki odwrotnej, mianowicie przejście po pewnym czasie (stabilna wersja) z Entity Framework na Nhibernate, pod kontem obecnej dyskusji (np. odpowiadając na pytanie: Czy łatwiej byłoby z użyciem Repozytorium?)
Omówienie zastosowanego wariantu
Chciałby tutaj omówić dość ogólnie dość popularny wariant użycia Repozytorium:
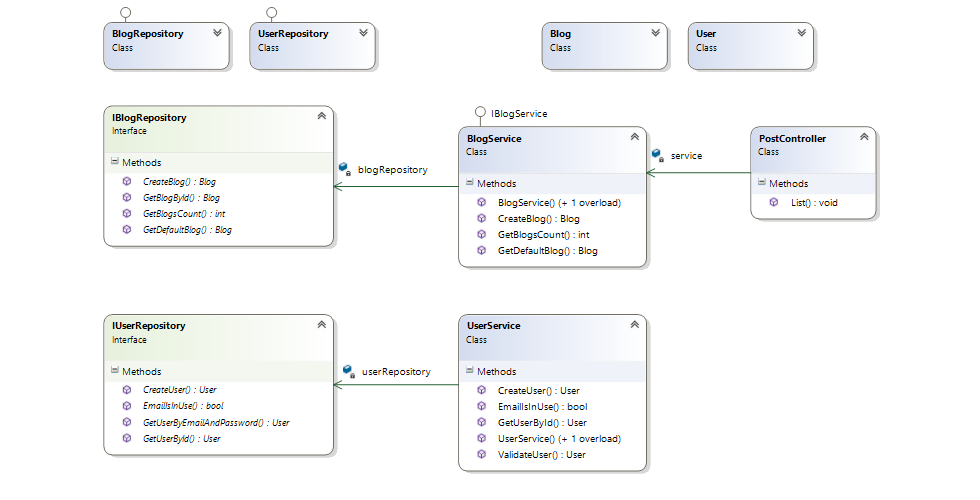
internal class UserRepository : IUserRepository
{
public User CreateUser(User userToBeCreated)
{
using (var context = new CodingBlogContext())
{
context.Users.Add(userToBeCreated);
context.SaveChanges();
}
return userToBeCreated;
}
public bool EmailIsInUse(string email)
{
using (var context = new CodingBlogContext())
{
return context.Users.Any(x => x.Email == email);
}
}
}
Plusy
- Udostępnia spójny interfejs wokół klasy User dla warstwy serwisowej
- Małe metody, skupiające się na jednym aspekcie (Single Responsibility)
- Eksponowane metody posiadają samo opisujące się nazwy, co podnosi czytelność kodu
Minusy
- Konieczność ciągłego rozbudowywania interfejsu – Fakt ten może przerodzić się w duży problem w większym projekcie, kiedy każdy dokłada swoją cegiełkę. Z czasem interfejs bardzo puchnie tworząc lekkiego „potwora”, który staje się trudny w utrzymaniu
- Serwis który potrzebuje wykonać operacje z klasą User i Blog potrzebuje co najmniej dwa Repozytoria – nie jest to duży problem, ponieważ z przy użyciu kontenera DI (Dependency Injection) możemy w łatwy sposób dotarczyć odpowiednie implementacje.
- Ukryta możliwość deklaratywnego programowania z użyciem LINQ na rzecz proceduralnego podejścia (metoda EmailIsInUse) – jakkolwiek może to mieć swoje plusy, jak wspomniana metoda gdzie nazwa funkcji lepiej wyraża akcję, jednakże w dłuższej perspektywie może okazać to się mniej praktyczne
- Problem z użyciem transakcji – w przypadku potrzeby sprawdzenia czy email jest obecnie używany i jezeli nie stworzenia użytkownika, dla przykładu:
public void CreateUserWithUniqueEmail(User userToBeCreated)
{
using(var scope = new System.Transactions.TransactionScope())
{
if (!_userRepository.EmailIsInUse(userToBeCreated.Email))
{
_userRepository.CreateUser(userToBeCreated);
}
scope.Complete();
}
}
Użycie klasy TransactionScope sprawi, że obie operacje objęte zostaną wspólną transakcją (ang. ambient transaction), która pozwala na zastosowanie semantyki bazodanowej (bez transakcji możemy odczytać że email nie jest używany i zaraz po tym inny wątek/thread zapisać użytkownika z podanym adresem. Może to prowadzić do wyjątków (SqlException) jeżeli email powinien być unikatowy).
Innym mniej powszechnym problemem związanym z użyciem TransactionScope, jest fakt, że klasa ta używa interfejsu COM-owego do DTC (Distrubuted Transaction Coordinator). Zatem aby móc używać TS system operacyjny powinien być odpowiednio skonfigurowany (w szczególności wspomniany DTC), co więcej jeżeli serwer bazodanowy i serwer aplikacji są na innych maszynach, wymaga to otwarcia dodatkowych portów DTC mogły się ze sobą komunikować. Może to być poważny problem przy wdrażaniu aplikacji u klienta (niestety doświadczyłem tego osobiście).
Jako alternatywę warto rozważyć bardziej ogólną formę:
public interface IReadOnlyRepository<T> : IDisposable
{
T FindByID(int id);
T FindOne(Expression<Predicate<T>> predicate);
T FindOne(Specification<T> specification); //przyklad uzycia LinqSpecs
//uzycie IQueryable ma swoje pros/cons
IQueryable<T> FindAll();
IQueryable<T> FindAll(Expression<Predicate<T>> predicate); //uzycie klasy Expression
IQueryable<T> FindAll(Specification<T> specification);
}
public interface IRepository<T> : IReadOnlyRepository<T>
{
void Create(T oEntity);
void Update(T oEntity);
void Delete(T oEntity);
void Copy(T oSource, T oTarget);
void Flush();
}
public class Repository<T> : IRepository<T>
{
public Repository(ISession session)
{
}
}
Przykład ten stosuje wzorzec Repozytorium w formie ogólnej, które jest dość zbliżona do obecnych interfejsów spotykanych we frameworkach ORM. Zawarte jest w nim wiele aspektów które mogą posłużyć jako inspiracja do rozważenia różnych rozwiązań.
Podsumowanie
Chciałbym podsumować dość krótko powtarzając wraz z Dino Esposito It Depends. Podejmując decyzję, odnośnie używania wzorców a szczególnie wzorca Repozytorium, pamiętajmy o tym że nasze podejście zależy od sytuacji, w której chcemy zastosować dane rozwiązanie. Mam nadzieje że ten tekst pomoże nam jako architektom i programistom podejmować bardziej świadome decyzje. Repozytorium w formie pierwszej (na przykładzie IUserRepository) może okazać jest dobrym rozwiązaniem, jeżeli projektujemy mały system i nie jesteśmy narażeni na omówione problemy. Z drugiej strony zaproponowane rozwiązanie powyżej, powinno być w dużej mierze użyte jako inspiracja do pokazania alternatywnego podejścia do tworzenia Repozytorium, z wykorzystaniem różnych technik (niekoniecznie wszystkich razem na raz). Użycie biblioteki ORM bezpośrednio może okazać się bardzo praktycznym posunięciem, szczególnie biorąc pod uwagę możliwości obecnych frameworków. Wreszcie użycie starannie zaprojektowanego Repozytorium w rozległym systemie z rozbudowaną logiką biznesową, gdzie modelowana domena znajduje się w centrum, może dostarczyć dużo korzyści w perspektywie czasu.



Repozytorium – stosować czy nie? | codingtv – video-blog programistyczny…
Dziękujemy za publikację – Trackback z dotnetomaniak.pl…
Bardzo porządny artykuł.
Trochę uszczegółowię swoją wypowiedź z komentarza pod poprzednim postem, który całą dyskusję zapoczątkował:
*) za bezsensowne uważam tworzenie warstwy repozytoriów NAD ORMem – w codingtv mamy do czynienia właśnie z tą sytuacją i w tym kontekście piszę swoje obserwacje
*) nieposiadanie repozytorium wcale nie wiąże się z bezpośrednim odwołaniem do danych na poziomie modelu domeny – tym zajmują się serwisy:
– rozpocznij transakcję
– pobierz agregat po ID (być może z odpowiednimi relacjami – eager loading)
– wywołaj metodę na agregacie (agregat w razie potrzeby sam sobie dociągnie potrzebne dane – lazy loading)
– zakończ transakcję (zapisując zmiany spowodowane metodą w agregacie)
*) jeśli nie mamy „modelu domeny” a tylko strzelamy w bazę CRUDem – to tym bardziej o wiele prościej będzie odwołać się bezpośrednio do danego ORMa niż dla każdego zapytania tworzyć osobną metodę
Ale koniec końców jak najbardziej zgadzam się z autorem: „it depends”. Zapewne są scenariusze, w których repozytorium ma uzasadnione zastosowanie. Tylko że nie jest to ten projekt.
I ostatnie zdanie:). Nie uważam bynajmniej, że powinniście coś zmieniać, czy że popełniliście błąd demonstrując tak popularne podejście „z repo” – dlatego też nie chciałem początkowo rozwijać tematu, sygnalizując jedynie swoją opinię, że w „prawdziwym” projekcie warto jest przystanąć na chwilę i zastanowić się nad alternatywami.
Kiedy ukaże się kolejne nagranie?
trochę musimy odpocząć po urlopie i w przyszłym tygodniu puścimy nowy odcinek 🙂
„pod kontem” – poprawcie
poprawione – dzięki 🙂
Coś długo Panowie odpoczywacie 😛
Niedługo zapomnimy co się działo w projekcie.
Po ciężkiej pracy należy cię dłuższy odpoczynek 🙂 Postaramy się w tym tygodniu opublikować kolejny odcinek.
„Nie zawsze będzie, bo zmieniając technologię z relacyjnych baz danych na bazę dokumentową, wkraczamy w inną przestrzeń przechowywania danych, gdzie „relacyjny” interfejs Repozytorium może nie mieć sensu.”
Nie do konca. Repozytorium ma za zadanie dostarczyc dane, potrzebne do tego aby utrzymac trwalosc obiektu ( persistence to sie chyba po angielsku nazywa ). I tylko tyle – nie interesuje nas, jakiego interfejsu uzywa to repozytorium, aby dane pozyskac. Moim zdaniem, takie repozytoirum powinno byc sparowane z fabryka obiektow , ktora na podstawie uzyskanych danych , stworzy gotowy, dzialajacy model domeny . W ten sposob, mamy odseparowane:
* Warstwe odpowiadajaca za trwalosc ( mozemy dowolnie podmieniac interfejs bazodanowy, a takze mozemy sobie pozwolic na dowolne rozszerzanie dostepu do danych wedle uznania – np, rozbic sobie dane z modelu domeny na wiele tabel )
* Warstwe odpowiadajaca za tworzenie obiektu – w skrocie, fabryka otrzymuje dane, a jej zadaniem jest stworzenie modelu domeny
* Sam model domeny biznesowej.
Ale to tam wiecie 😉 Swietny artykul, milo sie czytalo